LLM-as-a-Judge: Anatomia del Rulebook
Un rulebook non è una lista di metriche: è una mappa. Le 6 aree di valutazione per costruire un LLM-as-a-judge che misura ciò che conta davvero.


Quando si costruisce un sistema LLM da portare in produzione, prima o poi arriva una domanda scomoda: come sai che funziona bene? Il rulebook è la risposta strutturata a questa domanda. È il documento che definisce cosa deve valutare il giudice e secondo quali criteri — non una lista di metriche generiche, ma una mappa 🗺️ costruita attorno al sistema specifico che stai valutando.
Ogni dimensione inclusa ha una ragione: il tipo di sistema, gli input disponibili nella pipeline, le domande a cui vuoi rispondere.
Aree di valutazione 🧭
Dove c’è giudizio, c’è rumore, e più di quanto non si pensi
- Noise, Daniel Kahneman
Lo psicologo Daniel Kahneman (1934-2024) in "Noise: A Flaw in Human Judgment" distingue tre tipi di rumore nel giudizio umano: il level noise — visioni diverse sullo stesso compito — il pattern noise — reazioni diverse agli stessi elementi — e l'occasion noise — variazioni che dipendono non dal caso, ma da chi giudica e quando. La stessa frammentazione si ripropone nella valutazione degli LLM: scegliere le dimensioni sbagliate non produce errori riconoscibili, produce rumore.

Orientarsi fra le dimensioni di valutazione non è immediato. La scelta dipende da tre fattori — il tipo di sistema che stai valutando, gli input disponibili nella pipeline e le domande a cui vuoi rispondere.
Un chatbot generico richiede dimensioni diverse rispetto a un sistema RAG, un agente multi-step o un modello di code generation, e anche all'interno della stessa architettura non tutte le dimensioni sono sempre applicabili. Alcune sono universali, come correctness o relevance. Altre sono valutabili solo se il giudice dispone degli input giusti — la faithfulness non può essere misurata senza il contesto recuperato, la accuracy non può essere valutata senza un ground truth ⭐.
Per questo le dimensioni vanno raggruppate in aree di valutazione 🧭coerenti — insiemi che condividono la stessa logica, gli stessi input richiesti, gli stessi tipi di sistema a cui si applicano, le stesse domande a cui cercano di rispondere.
Sapere a quale area appartiene una dimensione è il modo più rapido per capire quando includerla nel rulebook — e quando lasciarla fuori.
Output quality ✅
Prima di chiederti se il modello è fedele alle fonti o sicuro per il deployment, c'è una domanda più semplice — la risposta è corretta, pertinente, utile, ben formulata? Output quality ✅ è l'area di valutazione più immediata da misurare. Molte delle sue dimensioni — coherence, fluency, clarity — non richiedono ground truth né contesto esterno. Il giudice lavora sulla coppia domanda-risposta, e questo è sufficiente.
Quanto si avvicina il coefficiente di Spearman all'umano? 🤔
G-Eval è un framework che utilizza LLM (come GPT-4) con Chain-of-Thought (CoT) per assegnare punteggi a testi basandosi su dimensioni come coherence, consistency e fluency.
I ricercatori chiedono a esperti di dominio umani di assegnare un punteggio da 1 a 5 a un set di testi, chiedono lo stesso a G-Eval e calcolano la correlazione di Spearman tra i due ranking. Ma come facciamo a sapere se G-Eval è affidabile? Proprio attraverso la correlazione di Spearman, che misura quanto due classifiche si assomigliano, dove 1 significa accordo perfetto e 0 assenza di relazione.
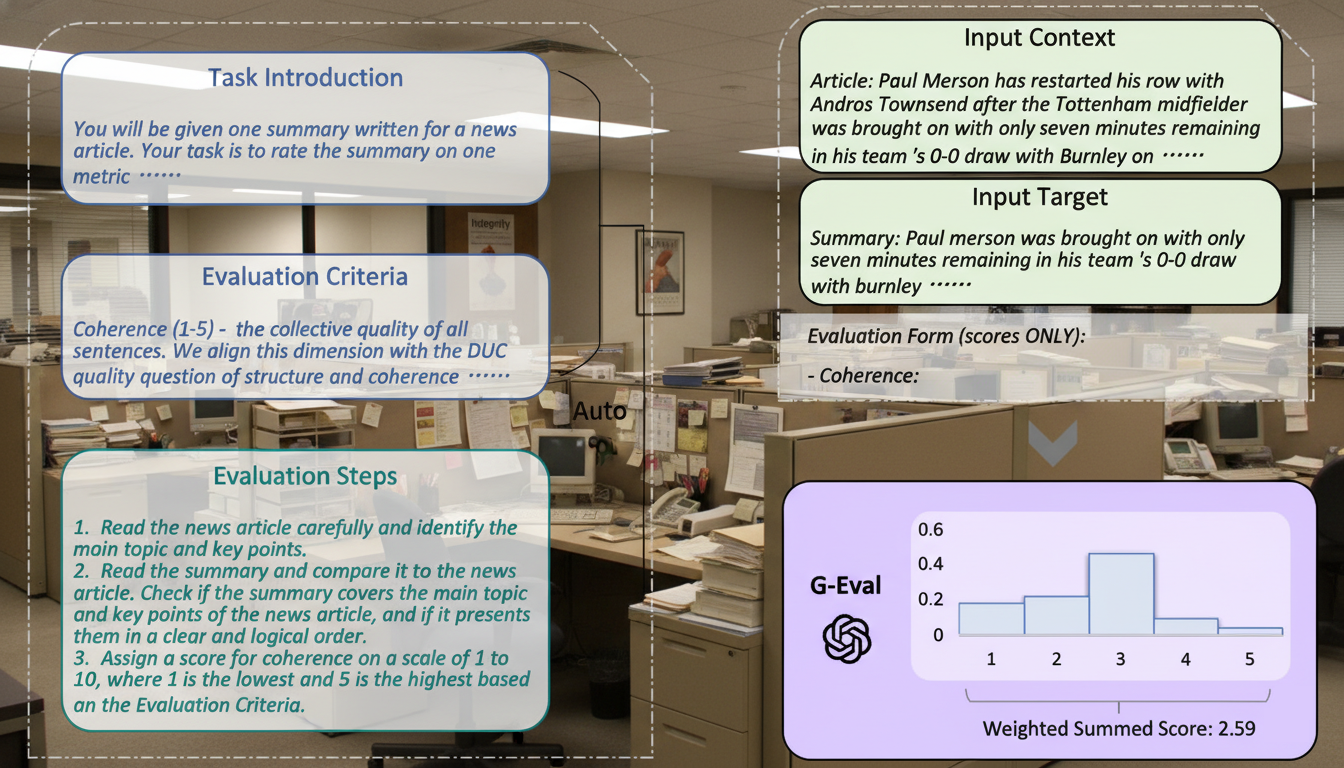
I dati di G-Eval (Liu et al., 2023), lavorando sulla coppia domanda-risposta, mostrano una correlazione di Spearman di 0.514 con valutatori umani su task di summarization — il risultato più alto al momento della pubblicazione. Quindi 0.514 indica che il giudice LLM e i valutatori umani tendono a ordinare le risposte nello stesso modo, pur non coincidendo esattamente.
Punto di partenza 📍
Quest'area di valutazione è il punto di partenza obbligato per qualsiasi rulebook, ma non è sufficiente da sola. Nei sistemi RAG, ad esempio una risposta fluente e pertinente può comunque essere infedele alle fonti — e per misurare questo serve un'area diversa.
Faithfulness 🔗
Una risposta può essere corretta in astratto e sbagliata al tempo stesso. In Il talento di Mr. Ripley (Anthony Minghella, 1999 — dal romanzo di Patricia Highsmith, 1955), Tom Ripley costruisce una delle impostture più elaborate della narrativa moderna: dopo aver ucciso Dickie Greenleaf, assume la sua identità, falsifica lettere, crea una corrispondenza fittizia tra sé e la vittima, si presenta in hotel come Dickie in un posto e come se stesso in un altro. Ogni singola affermazione che produce è internamente coerente, grammaticalmente corretta, plausibile nel tono.
Il problema non è la qualità dell'output — è che non c'è nulla di reale a sostenerlo. Ripley non mente male: mente senza fonti. Ed è esattamente il tipo di fallimento che Faithfulness 🔗 è costruita per rilevare.

Nei sistemi RAG, ciò che conta non è solo cosa dice il modello, ma se lo dice perché le fonti lo supportano. Una risposta fluente e pertinente può essere allo stesso tempo completamente slegata dal contesto recuperato — proprio come le lettere di Ripley: convincenti, ben scritte, e fabricate dall'inizio alla fine. Le dimensioni di quest'area — groundedness, hallucination, citation correctness — richiedono sempre che il giudice abbia accesso al contesto recuperato. Senza di esso, non può verificare se un'affermazione è ancorata alle fonti o semplicemente inventata.
Un giudice che valuta solo la coppia domanda-risposta, senza il contesto, è nella posizione di chi riceve una lettera di Ripley: può giudicarla ben scritta, ma non può sapere se corrisponde a qualcosa di reale.
Niente contesto, niente fedeltà
Il contesto recuperato non è un input opzionale, è la condizione necessaria perché la valutazione abbia senso come dimostrato anche da FaithJudge (Tamber et al., 2025), un framework LLM-as-a-judge sviluppato da Vectara che usa esempi di hallucination annotati da umani per valutare la fedeltà al contesto recuperato su task di summarization, question-answering e data-to-text generation.
Vectara pubblica dal 2023 un hallucination leaderboard — una classifica pubblica che misura, modello per modello, quante volte un LLM introduce informazioni non supportate dalle fonti — e i dati mostrano che i modelli che producono risposte plausibili ma non ancorate al contesto non vengono rilevati dai metodi di valutazione che non hanno accesso al contesto stesso.
Safety & alignment 🛡️
Una risposta imprecisa è un problema di qualità. Una risposta dannosa è un problema di natura diversa — e trattarla allo stesso modo è un errore che i sistemi in produzione non possono permettersi.

Nell'episodio "Dunder Mifflin Infinity" , Michael Scott segue alla lettera le istruzioni del GPS della sua auto a noleggio — e guida dritto nel Lago Scranton. Il GPS non stava sbagliando: le coordinate erano corrette, le istruzioni coerenti. Mancava un livello che dicesse aspetta, c'è un lago davanti. È esattamente la differenza tra un sistema impreciso e un sistema senza guardrail: il primo produce output di bassa qualità, il secondo esegue correttamente fino in fondo — e porta tutto il resto con sé.
Safety & alignment 🛡️ è l'area costruita per questo tipo di errore, valutando se il modello si comporta in modo sicuro, equo e conforme alle policy del sistema. Molte delle sue dimensioni — safety, toxicity, bias — possono essere misurate direttamente sulla risposta, senza riferimenti esterni. Ma richiedono un giudice ben calibrato su cosa costituisce contenuto problematico nel contesto specifico del sistema.
Una risposta che viola le policy di un assistente medico può essere perfettamente accettabile in un altro contesto — e questa variabilità è esattamente ciò che rende la calibrazione del giudice un passaggio non delegabile.
Offline eval e real-time guardrail
Le dimensioni di Safety & alignment 🛡️possono essere usate in due modi strutturalmente diversi. Come strumento di valutazione offline, servono ad analizzare batch di interazioni passate, identificare pattern di fallimento e calibrare il giudice. Come guardrail in produzione, devono invece operare prima che l'output raggiunga l'utente, con vincoli stringenti di latenza. La scelta non è neutra: un giudice LLM accurato richiede più compute e più contesto di quanto sia sostenibile in real-time.
Usare lo stesso giudice LLM per entrambi i ruoli è spesso un errore: un giudice accurato richiede più risorse e più contesto di quanto sia sostenibile in un sistema real-time. Ad esempio i sistemi che operano in produzione su scala — con migliaia di richieste simultanee — tendono per questo a separare i due ruoli: modelli classificatori più leggeri per i controlli in tempo reale e giudici LLM più sofisticati per l'analisi offline.
Valutazione continua
La ricerca recente conferma quanto sia necessario: Zou et al. in "Improving Alignment and Robustness with Circuit Breakers" (2024) mostrano che le tecniche standard ("refusal training") per insegnare al modello a rifiutare richieste problematiche vengono spesso aggirate da input costruiti appositamente per ingannarlo — rendendo la valutazione continua non un'opzione, ma una necessità strutturale.
Un'analisi comparativa condotta da Bud Ecosystem su soluzioni di guardrail in produzione (2024–2025) mostra che la maggior parte dei sistemi commerciali presentano vulnerabilità significative. Attacchi che usano input offuscati, variazioni linguistiche o prompt in lingue diverse dall'inglese raggiungono tassi di bypass che in alcuni casi superano il 70%. Anche soluzioni ampiamente adottate come Meta's Prompt-Guard-86M risultano aggirabili con perturbazioni semplici, come l'aggiunta di spazi tra i caratteri. Questo non significa che i guardrail siano inutili — significa che non possono essere trattati come una soluzione statica. È anche l'area che più di ogni altra richiede che chi calibra il giudice abbia una conoscenza profonda del dominio applicativo.
Un sistema di customer service bancario, un assistente medico e un chatbot educativo per minori richiedono definizioni di "danno" radicalmente diverse. Un assistente medico che suggerisce un dosaggio farmacologico senza disclaimer viola le regole di un sistema sanitario, ma la stessa risposta potrebbe essere perfettamente accettabile in un contesto di ricerca.
Valutare se il modello rispetta le regole del sistema in cui opera — senza aver prima specificato quelle regole, con esempi concreti di cosa passa e cosa non passa — produce un giudice che valuta in modo incoerente, indipendentemente da quanto sia potente il modello sottostante.
Reasoning quality 🧠
Un modello può arrivare alla risposta giusta per le ragioni sbagliate. E in contesti ad alto rischio — supporto medico, legale, finanziario — il percorso conta quanto il risultato.
Reasoning quality 🧠 è l'area che valuta non cosa il modello risponde, ma come ci arriva. Le sue dimensioni — reasoning depth, logical consistency, comprehensiveness — misurano se il ragionamento è profondo, coerente e completo. Non basta che la conclusione sia corretta: deve essere sostenuta da un filo logico che regge all'esame.
Il problema del ragionamento plausibile
Considera questo scenario: un sistema di supporto medico risponde correttamente che un farmaco non va assunto a stomaco vuoto. Ma lo giustifica con un meccanismo farmacologico sbagliato.
Un giudice che valuta solo la correttezza dell'output segna la risposta come corretta. Un giudice calibrato su Reasoning quality la segna come fallimento — perché un utente che interiorizza quel faulty reasoning applicherà la stessa logica in modo sbagliato la prossima volta. Questo è il tipo di errore che rende Reasoning quality difficile da valutare in modo affidabile.
Il paper Finding Blind Spots in Evaluator LLMs with Interpretable Checklists (2024) costruisce un benchmark con risposte corrette e versioni perturbate — stessa conclusione, reasoning difettoso — e verifica se i giudici LLM riescono a penalizzarle.
Il risultato: GPT-4-turbo, il modello più performante del benchmark, non riesce ad assegnare un punteggio più basso alle risposte con reasoning perturbato più del 50% delle volte sulle categorie di coherence, factuality e instruction-following. Gli altri modelli fanno peggio.
Il computer scientist Eugene Yan, nella sua analisi empirica degli LLM-evaluator ("Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge)", 2024), riassume il problema in modo netto: i giudici LLM tendono a valutare la superficie dell'output — fluency, lunghezza, struttura — più della qualità del ragionamento sottostante.
I giudici fine-tuned, in particolare, mostrano una correlazione peggiore con le valutazioni umane esperte proprio sulle dimensioni che richiedono un'analisi più profonda.
Quando includerla nel rulebook
Reasoning quality non è una dimensione universale. Per un chatbot di customer service che risponde a domande di prodotto, la qualità del reasoning è raramente critica. Va inclusa quando il sistema opera in domini dove l'utente potrebbe agire sulla base del reasoning — non solo della conclusione — o quando l'output deve poter essere giustificato a terzi.
È anche l'area che richiede il lavoro di calibrazione più esteso. Definire in astratto cosa costituisce un buon reasoning depth non basta: serve una rubrica con esempi concreti di reasoning sufficiente e insufficiente nel dominio specifico, preferibilmente annotati da un domain expert. Senza questo, il giudice valuterà in modo incoerente — e l'incoerenza in questa area è particolarmente difficile da rilevare, perché i punteggi possono apparire ragionevoli anche quando non lo sono.
Agent evaluation 🔍
Valutare un agente con le metriche di un chatbot è come giudicare una partita di scacchi guardando solo l'ultima mossa. Il risultato finale dice poco — quello che conta è la sequenza di decisioni che lo ha prodotto.
Agent evaluation 🔍 nasce dalla necessità di valutare sistemi che non si limitano a generare testo, ma pianificano, scelgono strumenti, eseguono azioni e si auto-correggono in sequenze multi-step. L'unità di analisi non è l'output finale ma l'intera trace, con tutte le decisioni intermedie che l'hanno prodotta.
Le dimensioni di quest'area richiedono che il giudice legga l'intera sequenza di azioni — non solo il risultato finale.
La trace non è un log: è il dato di valutazione
In Memento (Christopher Nolan, 2000), Leonard Shelby indaga sull'assassinio di sua moglie nonostante un'amnesia anterograda grave: non riesce a formare nuovi ricordi. Per compensare, costruisce un sistema esterno — fotografie polaroid annotate, biglietti scritti a mano, tatuaggi sul corpo.

Il problema non è che Leonard non sappia ragionare: è che senza accesso alla sequenza completa degli eventi, ogni sua decisione è priva di contesto. Agisce correttamente in base a ciò che vede, ma non può valutare se ciò che vede è affidabile — perché non ha registrato come ci è arrivato. È la stessa condizione in cui si trova un sistema di valutazione senza una trace strutturata.
Prima di chiedersi come valutare un agente, occorre rispondere a una domanda più concreta: cosa viene registrato durante l'esecuzione? Senza una trace strutturata — che includa non solo l'output finale ma ogni chiamata a strumenti, ogni step di ragionamento intermedio e i relativi metadati — la maggior parte delle dimensioni in questa tabella non può essere misurata. Agent path evaluation richiede la sequenza completa delle azioni. Tool selection richiede di sapere quale strumento è stato chiamato e con quali parametri. Agent reflection richiede di vedere come l'agente ha gestito errori o risultati inattesi.
Questo significa che includere Agent evaluation 🔍 nel rulebook richiede un investimento parallelo nell'osservabilità del sistema: il logging non può essere aggiunto in un secondo momento. Va progettato insieme alla pipeline — con la stessa attenzione con cui Leonard sceglie cosa tatuarsi, sapendo che nel momento in cui avrà bisogno di quella informazione, non ci sarà modo di tornare indietro a recuperarla.
Quanto è determinista il task? Dipende dal giudice
Non tutti i task di un agente ammettono una risposta verificabile. Un agente che prenota un volo ha un output atteso chiaro — la prenotazione è andata a buon fine o no — e la valutazione può appoggiarsi ad asserzioni di codice.
Un agente che supporta un utente nella risoluzione di un problema complesso produce invece un output aperto, dove il percorso conta quanto il risultato e non esiste un ground truth di riferimento. Questa distinzione cambia radicalmente il tipo di giudice da costruire.
Per i task deterministici, un evaluator basato su regole o su corrispondenza esatta è spesso sufficiente — e preferibile, perché più rapido e più controllabile. Per i task non deterministici, serve un giudice LLM capace di valutare la qualità del ragionamento e la coerenza del percorso, con criteri che devono essere definiti esplicitamente nel rulebook prima di iniziare. È l'area più giovane del rulebook e quella con i confini meno definiti.
I framework di valutazione per agenti sono ancora in evoluzione, e includere queste dimensioni oggi significa accettare che i criteri di giudizio si affineranno nel tempo.
Task-specific 🎯
It's not the plane, it's the pilot
Trent'anni dopo il primo film, Tom Cruise torna a interpretare Pete "Maverick" Mitchell in Top Gun: Maverick (Joseph Kosinski, 2022). La missione assegnata ai piloti ha criteri di valutazione precisi e non negoziabili: quota minima, velocità massima, angolo di attacco esatto sul bersaglio. Nessuna di queste metriche vale fuori da quella missione — e nessuna metrica generica sarebbe stata sufficiente a misurarla.

Task-specific 🎯 funziona allo stesso modo. Alcune dimensioni di valutazione hanno senso solo nel contesto per cui sono state definite, e non trovano posto in nessuna delle aree precedenti.
Tra tutte le aree di valutazione, Task-specific 🎯 è l'unica che non può essere definita senza un domain expert nella fase di calibrazione. Non va inclusa di default: va costruita dopo aver capito cosa le altre aree non catturano. Un rulebook non è completo perché include tutto — è completo perché non include nulla di superfluo.
Un rulebook non è una checklist
Un rulebook non si costruisce partendo dalle dimensioni — si costruisce partendo dalle domande. Cosa deve saper fare il sistema? Quali input ha a disposizione il giudice? Dove un errore ha conseguenze reali?

Le sei aree di valutazione descritte in questo articolo non sono un checklist da compilare dall'alto verso il basso. Sono un vocabolario. Sapere che esiste Faithfulness non significa includerla sempre — significa riconoscere quando il tuo sistema ne ha bisogno. Lo stesso vale per Reasoning quality, per Agent evaluation, per Task-specific.
Da dove si comincia? 🤔
Se stai costruendo un rulebook per la prima volta, la domanda più utile non è "quali dimensioni devo includere?" — è "quale tipo di errore non posso permettermi?"
Un assistente medico che alucina un dosaggio è un errore di Faithfulness. Un agente che compie dieci step quando ne bastano tre è un problema di Agent path evaluation. Un chatbot di customer service che risponde in modo tecnicamente corretto ma freddo è una questione di Tone appropriateness, e appartiene a Task-specific.
Partire dall'errore peggiore non è pessimismo operativo — è il modo più rapido per capire quale area del rulebook vale la pena costruire per prima, e quali possono aspettare.
Il rulebook come strumento
Il rischio più frequente non è costruire un rulebook sbagliato — è costruire un rulebook che smette di essere usato. Succede quando le dimensioni sono definite in astratto, senza esempi concreti di cosa passa e cosa non passa nel sistema specifico.
Un giudice calibrato su definizioni generiche produce punteggi che sembrano ragionevoli ma non guidano nessuna decisione: non dicono se il sistema è migliorato, non spiegano dove ha fallito, non orientano il lavoro di prompt engineering o fine-tuning.
Un rulebook vivo è quello che viene aggiornato quando il sistema cambia, quando emergono nuovi pattern di fallimento, quando il dominio applicativo si espande. Non è un documento di specifiche — è uno strumento di misurazione, e come ogni strumento di misurazione si calibra nel tempo.
Dove c'è giudizio senza struttura, c'è rumore.
Il rulebook è la struttura.
🔗 Sitografia
2023
[0] Cameron R. Wolfe, Chain of Thought Prompting for LLMs, 24/04/2023
2024
[0] Cameron R. Wolfe, A Practitioners Guide to Retrieval Augmented Generation (RAG), 05/02/2024
[1] Aparna Dhinakaran, Evan Jolley, Why You Should Not Use Numeric Evals for LLM As a Judge, Arize, 08/03/2024
[2] Cameron R. Wolfe, Using LLMs for Evaluation, Blog, 22/07/2024
[3] Cameron R. Wolfe, Finetuning LLM Judges for Evaluation, Blog, 02/12/2024
2025
[0] Dave Davies, LLM evaluation: Metrics, frameworks, and best practices, Weights & Biases, 12/02/2025
[1] Pratik Bhavsar, What Is the G-Eval Metric? How It Helps With AI Model Monitoring and Evaluation, Galileo, 12/03/2025
[2] Arun Mohan, G-Eval: Rethinking LLM Assessment with GPT-4, Medium, 28/03/2025
[3] James Zhu et Al., LLM-as-Judge: Evaluating and Improving Language Model Performance in Production, Twilio, 01/05/2025
[4] Dave Davies, LLM evaluation metrics: A comprehensive guide for large language models, Weights & Biases, 03/05/2025
[5] Vision X, LLM-as-a-Judge: The Future of Evaluating AI Models with Accuracy and Scale, Vision X, 09/05/2025
[6] Redazione, A Survey on LLM Guardrails: Part 1, Methods, Best Practices and Optimisations, Bud Ecosystem, 17/06/2025
[7] Notre Dame–IBM Tech Ethics Lab, Can we trust AI to judge? Two research teams explore the opportunities and limitations of LLM-as-a-Judge, Blog Post, 24/07/2025
[8] Redazione, Evidence-Based Prompting Strategies for LLM-as-a-Judge: Explanations and Chain-of-Thought, Arize, 20/08/2025
[9] Sebastian Sigl, The 5 Biases That Can Silently Kill Your LLM Evaluations (And How to Fix Them), Personal Blog, 19/09/2025
[10] Sebastian Raschka, Understanding the 4 Main Approaches to LLM Evaluation (From Scratch), Head of AI, 05/10/2025
[11] Redazione, LLM-as-a-judge: a complete guide to using LLMs for evaluations, Evidently AI, 23/07/ 2025
[12] Jeffrey Ip, LLM-as-a-Judge Simply Explained: The Complete Guide to Run LLM Evals at Scale, Confident AI, 10/10/2025
[13] Kritin Vongthongsri, G-Eval Simply Explained: LLM-as-a-Judge for LLM Evaluation, Confident AI, 10/10/2025
[14] Redazione, F.A.Q on LLM judges: 7 questions we often get, Evidently AI, 31/10/2025
[] Doug Turnbull, LLM Judges aren’t the shortcut you think, Softwaredoug, 02/11/2025
[15] Juan C Olamendy, Using LLM-as-a-Judge to Evaluate Agent Outputs: A Comprehensive Tutorial, Medium, 05/11/2025
[16] Devaraj Durairaj, LLM as a Judge — A Practical, Human Guide for Engineers and Curious Minds, Medium, 26/11/2025
[17] Nagesh Singh Chauhan, LLM-as-a-Judge: Rethinking How We Evaluate AI Systems, 25/12/2025
2026
[0] Marlies Mayerhofer, LLM-as-a-Judge Evaluation: Complete Guide, Langfuse, 12/02/2026
🔎 Papers
2023
[0] Wang, Peiyi et al., Large language models are not fair evaluators, arXiv preprint arXiv:2305.17926, 2023
[1] Yang et al., G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment, arXiv:2303.16634, 2023
[2] Zheng et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, arxiv:2306.05685, NeurIPS, 2023. Il paper fondamentale su LaaJ. Dimostra che GPT-4 raggiunge oltre l'80% di accordo con le preferenze umane (lo stesso livello osservato tra due valutatori umani). Definisce LaaJ come "a scalable and explainable way to approximate human preferences." . Introduce pairwise comparison e single-answer grading come protocolli di valutazione.
2024
[0] , RevisEval: Improving LLM-as-a-Judge via Response-Adapted References, arXiv:2410.05193, 2024
[1] Gu et al., A Survey on LLM-as-a-Judge, arxiv:2411.15594, 2o24. Survey completo che copre scalabilità, costo-efficacia, consistenza e strategie per migliorare l'affidabilità dei giudici LLM.
[2] Ye et al., Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge, arxiv:2410.02736 , 2o24. Quantifica i bias dei giudici LLM (posizione, verbosità, self-enhancement).
2025
[0] Li et al., Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge, 2025
[1] Li et al., From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, arxiv:2411.16594 , 2025. Survey che documenta come le metriche tradizionali (matching-based) falliscano in scenari open-ended e dinamici, e come gli LLM offrano valutazioni multi-dimensionali.
[2] Tamber et al., Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards, arXiv:2505.04847, EMNLP Industry Track 2025, 06/11/2025. Introduce FaithJudge, un framework LLM-as-a-judge che usa esempi di hallucination annotati da umani per valutare la fedeltà al contesto recuperato in sistemi RAG su task di summarization, QA e data-to-text generation. Mantiene un hallucination leaderboard aggiornato che benchmarka i principali LLM sulla capacità di non introdurre informazioni non supportate dalle fonti.