Domain-Driven AI: come progettare un sistema multi-agente verticale
Prima di scegliere un modello, bisogna capire il dominio. Ecco come il DDD trasforma il design di sistemi multi-agente verticali.


L'arrivo degli LLM rappresenta un cambiamento fondamentale, paragonabile all'arrivo del web alla fine degli anni '90, ma con una velocità senza precedenti. Eppure molte soluzioni AI adottano ancora un approccio puramente model-centric: si sceglie un modello potente e lo si applica a problemi complessi, nella speranza che la sua capacità statistica colmi le lacune di ciò che non conosce.
Questo modo di procedere mostra subito i suoi limiti nei settori verticali — pubblica amministrazione, diritto, finanza, medicina, industria — dove la semplice plausibilità del testo non basta. In questi contesti servono accuratezza, verificabilità e coerenza.
Requisiti che richiedono un approccio più strutturato.
Dominio: la conoscenza che non sta nei dati🔍
Prima di scegliere un modello LLM, progettare una pipeline RAG o valutare il fine-tuning, il punto di partenza è il dominio, ovvero l'insieme di conoscenze, regole, relazioni e linguaggio specialistico che definisce un settore specifico. Non è un concetto astratto — è il modo in cui un avvocato distingue un appalto da una concessione, in cui un tecnico identifica un guasto da un pattern di vibrazioni, in cui un medico interpreta un referto, in cui un broker assicurativo distingue tra premio, massimale e franchigia.

È la knowledge che gli esperti di settore (domain experts) danno per scontata, ma che un modello generico non possiede. Ed è esattamente questa conoscenza che va progettata, prima ancora di scrivere codice.
Un cambio di metodo: Domain-Driven AI
Dobbiamo comprendere il dominio, smontarlo pezzo per pezzo e ricostruirlo in una forma condivisibile dagli esseri umani e interpretabile dalle macchine. In pratica, significa mappare la **knowledge base del dominio** — identificare le entità fondamentali, le fonti normative, i manuali tecnici, il corpus documentale e, soprattutto, il linguaggio specialistico del settore.
La soluzione non sta in modelli sempre più grandi. Sta in un cambio di metodo, in quello che chiamo Domain-Driven AI. Seguendo lo spirito del *Domain-Driven Design (DDD) di Eric Evans (2003), questo approccio assume che la modellazione rigorosa della **conoscenza esplicita** debba precedere qualsiasi riga di codice. Invece di chiedere a un modello generico di improvvisare su tutto, l'obiettivo diventa **progettare il dominio stesso** — strutturarne la conoscenza tramite **knowledge graph** o **ontologie** — e costruire un sistema su misura che integri LLM, meccanismi di retrieval e procedure di verifica.
Il dato non basta: Data-Centric AI
Questo cambio di prospettiva è coerente con quanto sostenuto da Andrew Ng: le organizzazioni dovrebbero smettere di inseguire modelli sempre più potenti e concentrarsi invece sulla qualità dei dati che li alimentano. È la stessa direzione del movimento Data-Centric AI (DCAI), che sposta l'attenzione dalla crescita indiscriminata dei modelli alla cura della qualità, della coerenza e della struttura dei dataset. Significa investire più risorse nella raccolta, pulizia, etichettatura e arricchimento dei dati, affinché questi rappresentino in modo accurato il problema reale che il sistema è chiamato a risolvere.

Il punto di arrivo, in entrambi i casi, è lo stesso: prima viene il dominio, poi tutto il resto. Sistemare i dati è necessario, non sufficiente. Perché dati puliti e ben etichettati su un dominio che non si conosce restano dati opachi: sai che sono corretti, ma non sai cosa significano davvero.
- Quali entità rappresentano?
- Quali relazioni implicano?
- Quali regole devono rispettare?
Senza una risposta a queste domande, i dati restano raw data. E le risposte le conosce solo il dominio.
Ubiquitous language: parlare la stessa lingua
Immaginate di trovarvi smarriti in una cultura straniera, dove le parole e i gesti non hanno lo stesso significato e ogni tentativo di comunicazione si traduce in un equivoco. È questa la sensazione al centro di Lost in Translation, il film di Sofia Coppola, dove due personaggi si ritrovano a Tokyo accomunati non solo dalla solitudine, ma dalla frustrazione di vivere in un mondo in cui il linguaggio è una barriera insormontabile.
Il film cattura magistralmente quella sensazione di isolamento che emerge quando manca un terreno comune — anche nelle situazioni più banali.
Nel mondo dello sviluppo di sistemi AI, la stessa frattura esiste, ed è molto più costosa. Quando un progetto manca di un linguaggio condiviso, ogni figura professionale traduce per le altre: gli sviluppatori interpretano i requisiti degli esperti di dominio, questi ultimi cercano di decodificare il linguaggio tecnico, e nel mezzo si perdono sfumature, vincoli, significati.
Eric Evans descrive questa dinamica con precisione:
On a project without a common language, developers have to translate for domain experts. Domain experts translate between developers and still other domain experts. Developers even translate for each other. Translation muddles model concepts, which leads to destructive refactoring of code.
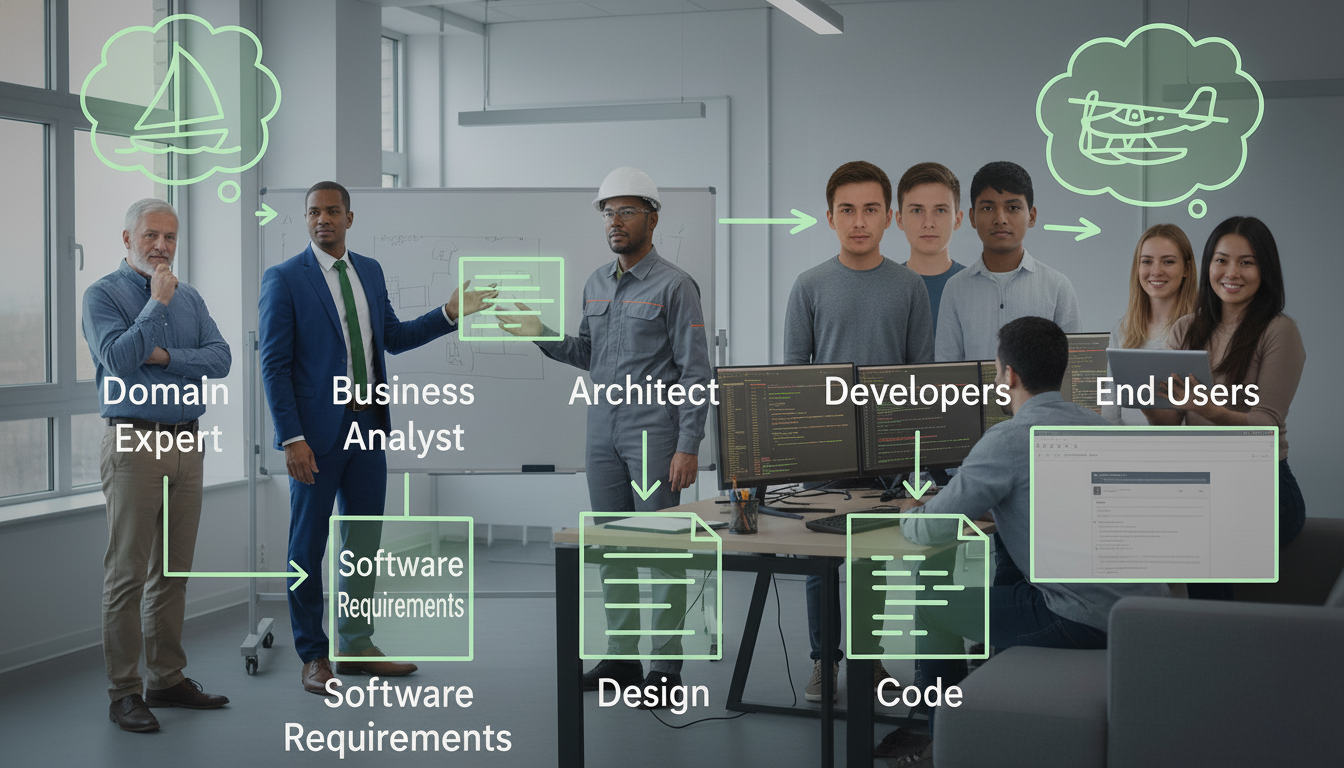
La traduzione costante non solo rallenta il lavoro: introduce distorsioni che compromettono la qualità del modello e del codice. Il dominio del problema perde espressività, i requisiti si fanno vaghi, e l'implementazione tecnica si cristallizza su rappresentazioni distorte del contesto reale.
L'ubiquitous language serve esattamente a evitare questa frattura. Non è solo una best practice comunicativa: è il fondamento che garantisce che le risposte generate da un sistema AI rispettino i vincoli semantici, tecnici e normativi del mondo reale, invece di produrre testi "verosimili" ma concettualmente sbagliati. Un linguaggio condiviso attraversa tutto il progetto: le conversazioni con i clienti, la documentazione, le interviste con gli esperti di dominio, i ticket di supporto. È il filo che tiene insieme persone e macchine.
Domain modeling: strutturare la conoscenza
Come modellare il dominio prima di costruire un Multi-Agent AI Systems (MAS)? Operativamente, si parte con una Domain Analysis: mappare i concetti, le entità, le relazioni, le regole, le fonti, i documenti e la terminologia che compongono il dominio. Da questa analisi deriva la costruzione di una knowledge base strutturata o semi-strutturata, ovvero un insieme di conoscenza organizzata in modo tale che sia leggibile dalle macchine.
Il domain modeling (ontologie, knowledge graph, ubiquitous language, etc) è il lavoro preparatorio che rende possibile — e ben fondato — il design di un sistema multi-agents (MAS).
Il filosofo e chimico Michael Polanyi sintetizzò questa sfida in una frase: "Sappiamo più di quanto sappiamo dire". La conoscenza tacita — il saper fare degli esperti — deve essere estratta e resa esplicita per diventare computabile. Il Knowledge Modeling è il processo con cui questo avviene: non si limita a caricare documenti in un database vettoriale, ma consiste nel strutturare un'architettura dati basata su:
- Ontologie e Vocabolari Controllati: Definire rigorosamente il significato dei termini (es. la distinzione giuridica tra "appalto" e "concessione") per eliminare le ambiguità.
- Knowledge Graphs (KG): mappare le relazioni logiche tra le entità. L'integrazione tra strutture a grafo e LLM — come dimostrato dalla ricerca su **GraphRAG** (Microsoft Research, 2024) — potenzia le capacità di ragionamento del sistema, superando i limiti del semplice recupero vettoriale.
- Tassonomie e Metadati: Creare schemi di classificazione che garantiscano un retrieval preciso, contestuale e granulare.
L'obiettivo è generare una Ground Truth modulare e scalabile: in caso di variazioni normative, è sufficiente aggiornare la knowledge base senza dover riaddestrare il modello.
Bounded Context: dividere il dominio
Una volta mappato il core domain (il dominio principale), il passo successivo è capire come dividerlo in subdomains. Non tutti i concetti appartengono allo stesso spazio semantico — e forzarli in un unico modello monolitico è esattamente il tipo di complessità che vogliamo evitare.
In un impianto industriale, la parola guasto ricorre continuamente — ma non ha lo stesso significato per tutti. Per il tecnico di campo, un guasto è un evento fisico osservabile: una vibrazione fuori soglia, un surriscaldamento, un'anomalia rilevata dai sensori. Per il project manager della manutenzione, lo stesso guasto è un elemento da schedulare: ha una priorità, una finestra temporale, una risorsa assegnata. Per il magazzino ricambi, è una richiesta di componente: ha un codice, una quantità, una giacenza da verificare. Tre contesti, tre modelli, tre definizioni legittime dello stesso termine.

Il Bounded Context (BC) è lo strumento che DDD ci offre per gestire questa divisione. Ogni bounded context è un confine esplicito all'interno del quale un insieme di concetti, regole e terminologia ha un significato preciso e stabile. Fuori da quel confine, lo stesso termine può significare qualcosa di diverso — e va bene così, purché il confine sia chiaro.
Il confine non è tecnico, ma semantico: se una parola ha lo stesso significato in due aree diverse, siete nello stesso contesto. Se può significare cose diverse, state lavorando su due bounded context distinti. È un confine linguistico prima ancora che architetturale.
Da Bounded Context ad Agente
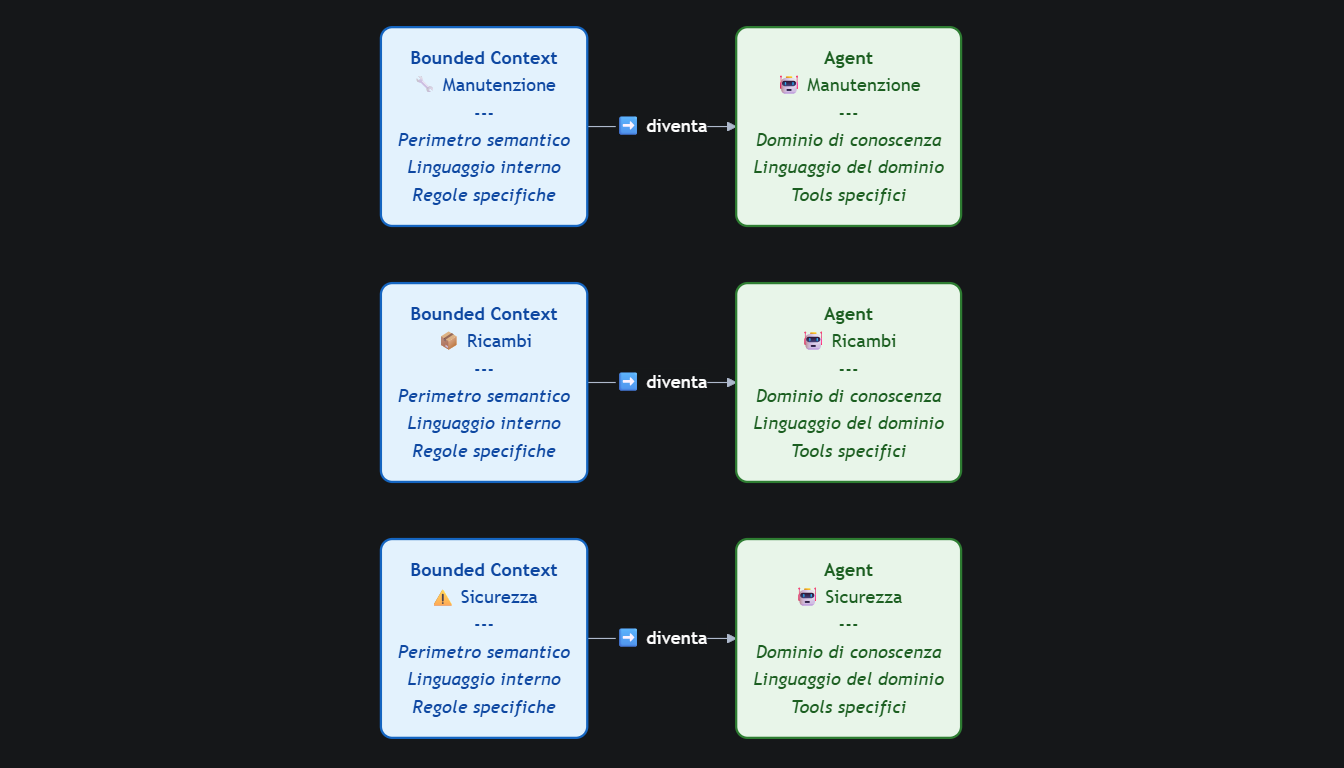
Ogni bounded context definisce un perimetro di conoscenza, un linguaggio interno coerente, un insieme di regole valide solo al suo interno. È la stessa struttura che, nel design di un sistema multi-agent, descrive un agente — un'unità autonoma che opera all'interno di un dominio preciso, con strumenti e conoscenza specifici per quel contesto.
La mappa dei bounded context diventa così la mappa degli agenti — favorendo la specializzazione (es. un agente per la "manutenzione", uno per i "ricambi") rispetto alla generalizzazione, e migliorando la precisione delle risposte.
Case study: Manutenzione industriale
Durante l'età vittoriana, le macchine venivano costruite per durare — ma non per essere "mantenute". Il concetto stesso di manutenzione preventiva semplicemente non esisteva: si parlava di riparazioni, usura, sostituzione di componenti.
Una semantica diversa, che riflette un modo diverso di concepire le macchine e la loro vita operativa.

Questa distanza tra linguaggi diversi — tecnico, storico, operativo — è la stessa che incontriamo oggi nella manutenzione industriale moderna, e che rende evidente la necessità di un ubiquitous language. In un impianto convivono manuali scritti vent'anni fa, documentazione aggiornata in momenti diversi, report redatti da tecnici con background differenti, ciascuno con il proprio gergo.
Costruire la knowledge base
Un sistema RAG generico faticherebbe a interpretare questa eterogeneità, generando risposte incoerenti o imprecise.
Un approccio Domain-Driven AI, invece, parte dalla costruzione di una knowledge base strutturata: una tassonomia completa delle componenti di una turbina, con ogni elemento collegato ai relativi codici di ricambio; un database in cui le tipologie di guasto sono mappate alle cause probabili e alle procedure correttive; un modello relazionale che lega i parametri dei sensori — temperatura, vibrazioni, pressione — agli stati operativi della macchina.
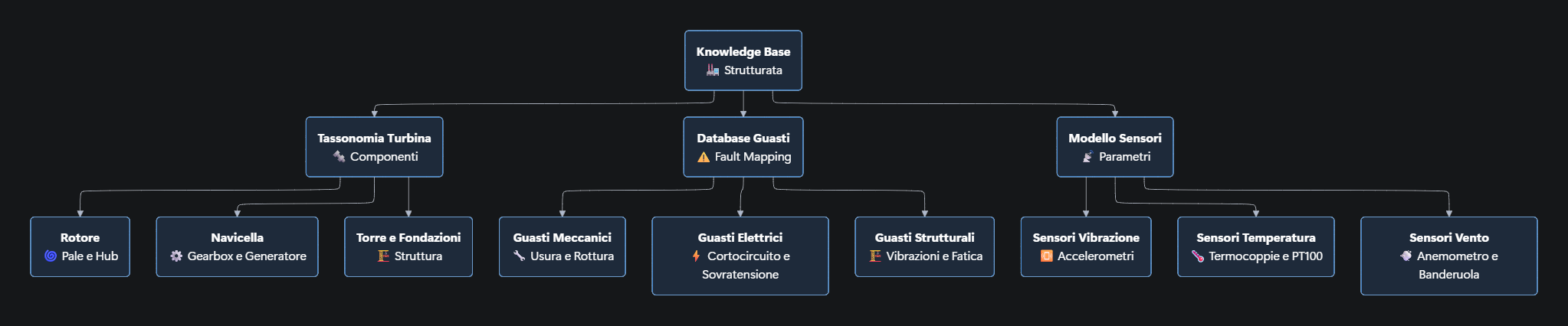
Accanto a questa struttura rigida, si costruisce una knowledge base semi-strutturata che, grazie ai metadati, resta comunque indicizzabile e interpretabile. Qui trovano posto i manuali di manutenzione segmentati per argomento — installazione, calibrazione, troubleshooting, sicurezza; i rapporti dei tecnici ripuliti e normalizzati per renderli confrontabili; le procedure operative riorganizzate in documenti sequenziali con riferimenti chiari alle norme interne.
Solo dopo aver costruito questo ubiquitous language — una visione condivisa, formalizzata e non ambigua del dominio industriale — si può innestare ad esempio una pipeline che combina un'agente RAG + LLM, sapendo che il modello potrà appoggiarsi a una knowledge base solida, coerente e verificabile.
Applicarlo al dominio industriale
Nel momento in cui abbiamo definito i bounded context del nostro dominio industriale (es. manutenzione, sicurezza, ricambi), abbiamo già la mappa degli agenti. Ogni agente è un bounded context — ha il proprio modello, linguaggio, regole, conoscenza.
Il linguaggio condiviso deve valere anche tra agenti diversi che si passano output. Se un agente "manutenzione" passa risultati a un agente "planner", i termini del dominio devono essere coerenti — esattamente quello che garantisce la knowledge base strutturata che abbiamo creato.
In un sistema multi-agent, il tooling può essere ottimizzato per dominio: ogni agente usa il modello più adatto al suo contesto — un agente legale usa un modello fine-tuned su testi giuridici, un agente di pianificazione usa un reasoning model.
Come si applica in pratica?
Se vogliamo passare dai Chatbot agli Agenti AI capaci di agire sul mondo reale, il Domain-Driven AI non è opzionale, è obbligatorio. Come procederei adesso?
- Inizierei con domain analysis: mapperei il dominio — concetti, entità, relazioni, dati, fonti, documenti, regole, terminologia.
- Raccoglierei o costruirei una knowledge base strutturata / semi-strutturata: normativa, documenti, manuali, moduli, dataset — in formato adatto al retrieval (testo, metadata, tabelle).
- Userei un approccio RAG "light": vector retrieval + LLM + verifica semplice — come prototipo per testare la fattibilità.
- Se il prototipo dà risultati, potrei evolverlo in qualcosa di più robusto: knowledge-graph, metadata strutturati, modulazione di dominio, interfaccia di QA, tool di validazione.
- Documenterei ogni passo: modello di dominio, criteri di selezione dati, metriche di qualità, casi d'uso, limitazioni — come base per un progetto scalabile.
- Definirei i pattern di orchestrazione: sequenziale (pipeline) per workflow deterministici come procedure di manutenzione, parallela per analisi multi-prospettiva (es. tre agenti che valutano un guasto da angolazioni diverse), manager/planner per scenari open-ended.
Il ruolo del domain expert
Il domain expert sarà coinvolto in due momenti successivi: nella definizione delle dimensioni rilevanti della valutazione (evaluation), e nella costruzione del ground truth⭐, assicurandosi che i dati coprano le situazioni reali con la giusta rappresentatività.
- Cosa distingue un'interazione riuscita da una fallita?
- Quali sono i casi critici che il sistema deve assolutamente gestire bene?
- Quali scenari sarebbero imbarazzanti o dannosi? 🤔
Queste stesse domande, seguendo la metodologia LLM-as-a-judge, diventeranno i criteri con cui configurare un giudice automatico: un modello che valuta gli output del sistema sulla base di rubriche costruite a partire dalla conoscenza del dominio. Non è più solo il prompt a incorporare l'expertise — è anche la valutazione stessa.
Un atto di umiltà
Il Domain-Driven AI non è una tecnologia: è un atto di umiltà. Significa ammettere che un modello, per quanto potente, non può compensare una conoscenza che non gli è mai stata trasmessa. Prima di scegliere un modello, costruire un indice vettoriale o scrivere un prompt, bisogna capire il dominio — smontarlo, formalizzarlo, renderlo condivisibile. È questo il lavoro che separa un sistema AI che convince nelle demo da uno che regge nel mondo reale.
🔗Sitografia
2014
[0] Philip Brown, What are Bounded Contexts and Context Maps in Domain Driven Design?, Cult3, 19/11/2014
2018
[0] Vadim Samokhin, DDD Strategic Patterns: How to Define Bounded Contexts, DZone, 06/01/2018
2022
[0] John Boldt, Domain Driven Design — The Ubiquitous Language, Medium, 15/04/2022
[1] Tomas Fernandez, Domain-Driven Design Principles for Microservices, Semaphore, 21/06/2022
2024
[0] Thomas Betts, Eric Evans Encourages DDD Practitioners to Experiment with LLMs, InfoQ, 18/03/2024
[1] Mohamed Yassin Jammeli, The Power of Ubiquitous Language in Software Development: Simplified, Medium, 05/06/2024
[2] Marco Zucca, Guida al Domain Driven Design, Neting, 28/06/2024
[3] Nikita Bhatt et al. , A Data-Centric Approach to improve performance of deep learning models, Nature, 27/09/2024
[4] Anthropic, Building effective agents, Engineering at Anthropic, 19/12/2024
2025
[0] James Croft, Applying domain-driven design principles to multi-agent AI systems, 14/08/2025
📺Videografia
2019
[0] Domain-Driven Design Europe , What is DDD - Eric Evans - DDD Europe 2019, Youtube, 21/12/2019
2022
[0] Data centric AI development From Big Data to Good Data Andrew Ng, Youtube, 19/07/2022
2023
[0] Bran Van der Meer, Ubiquitous Language, simplified, Youtube, 09/11/2023
2025
[0] Bytemonk, Domain-Driven Design: Bounded Contexts Explained! , Youtube, 20/04/2025